Dr. Nick Garabedian, Prof. Dr. Christian Greiner
Das Interesse an der Anwendung des maschinellen Lernens im Rahmen von Tribologieprojekten ist gestiegen. Gleichzeitig erkennen die politischen Entscheidungsträger, dass die zuverlässige Bereitstellung von Daten die Umsetzung größerer maschineller Lernprojekte unterstützt. FAIR-Daten bilden somit die Brücke zwischen den verschiedenen Laboraktivitäten und dem Einsatz moderner Algorithmen, mit denen einige der dringendsten Probleme gelöst werden können.
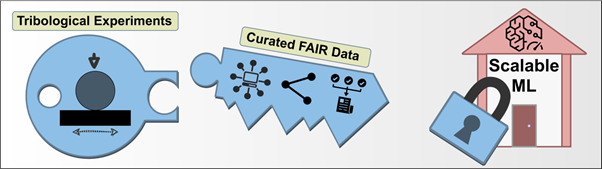
In einer Veröffentlichung in Nature Scientific Data [1] zeigt eine Gruppe von 14 Wissenschaftlern des MicroTribology Center μTC die notwendigen Schritte zur Erstellung eines FAIR-Datensatzes für die Tribologie auf. Die Generierung von FAIR-Forschungsdaten in der Tribologie ist aufgrund der außergewöhnlichen Interdisziplinarität des Fachgebiets eine besondere Herausforderung: Viele scheinbar triviale tribologische Probleme erfordern ein tiefes, aber dennoch ganzheitliches Verständnis der Prozesse und Mechanismen, die zwischen, an und unter berührenden Oberflächen ablaufen. Das Team wählte ein relativ standardmäßiges Stift-auf-Scheibe-Experiment und verfolgte den Arbeitsablauf, den eine Probe von der Ankunft als Rohmaterial bis zur Beanspruchung durch eine tribologische Belastung durchläuft. Die dabei entdeckten Herausforderungen führten zur Entwicklung eines kontrollierten Vokabulars, einer Ontologie, einer Software für die einfache Dateneingabe und der Schnittstelle zu einem elektronischen Laborjournal.
Derzeit setzt das Team seine Bemühungen fort, indem es produktionsreife Lösungen entwickelt, die die Masseneinführung von FAIR-Datenpraktiken in allen Labortätigkeiten ermöglichen sollen. Es wurde festgestellt, dass der erste und zuverlässigste Weg zur Erreichung dieses Ziels darin besteht, ein Werkzeug für die gemeinsame Erstellung von lokalen kontrollierten Vokabularen und Aufgabenontologien bereitzustellen. Das Tool heißt VocPopuli und soll im 4. Quartal 2022 veröffentlicht werden.
[1] Garabedian, N.T.; Schreiber, P.J.; Brandt, N.; Zschumme, P.; Blatter, I.L.; Dollmann, A.; Haug, C.; Kümmel, D.; Li, Y.; Meyer, F.; Morstein, C.E.; Rau, J.S.; Weber, M.; Schneider, J.; Gumbsch, P.; Selzer, M.; Greiner, C., Generating FAIR research data in experimental tribology, Scientific Data 9 (2022) Art. 315, 11 Seiten Link